导读
基本学习(可以跳过)
Java 十进制 二进制 八进制 十六进制表示
二进制表示: 0b00101000; 0b代表二进制。
八进制表示: 01234567; 0代表八进制。
十六进制表示:0x1a; 0x代表十六进制。
1 | int decimalInteger = 17; // 十进制 |
Java 进制转换
十进制变成二进制
Integer.toBinaryString(19);
Long.toBinaryString(19);
十进制变成八进制
Integer.toOctalString(19);
Long.toOctalString(19);
十进制变成十六进制
Integer.toHexString(19);
Long.toHexString(19);
数值型字符进制转换
Integer类、Long类
Integer.parseInt(“1a”, 16);
Integer.parseInt(“13”, 8);
Integer.parseInt(“10”, 2);
Integer.valueOf(“1a”, 16);
Integer.valueOf(“13”, 8);
Integer.valueOf(“10”, 2);
正文前餐
在开始之前,作者想说明一个知识点。
- 开发时使用charset。
- 无论是前端、客户端、后端开发,都接触到charset。
- 很多应用程序也需要去设置字符集,例如
mysql charset,http charset,tomcat charset
开发时使用charset,通常包含了字符集合(如:中简体文字符集合、英文字符集合)和字符编码二进制存储。
字符集规定了某类字符对应的二进制数值存放方式(编码),通过一个二进制数值 在某种字符集中寻找出对应代表的字符就是解码的过程。—– 引用细说字符集(CharSet)和字符编码(Encoding)
按照惯例,字符集和字符编码是一样的,因为按照一套的标准来定义要去收集哪些字符和将这些字符正确编码到一系列的代码单元(通常一个字符一个单元)。由于历史叫法习惯,我们把将一组字符编码成一系列八位字节数据的编码系统会使用字符集这个术语来表示。 —–引用wiki 字符集1
2
3
4JSP 设置charset
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
HTTP response ContentType设置charset
Content-Type: text/html; charset=utf-8
字符集|字符编码
基础概念介绍
字符 是一个信息单位,在计算机里面,一个中文汉字是一个字符,一个英文字母是一个字符,一个阿拉伯数字是一个字符,一个标点符号也是一个字符。 字符集 是字符组成的集合,通常以二维表的形式存在,二维表的内容和大小是由使用者的语言而定,是英语,是汉语,还是阿拉伯。 字符编码 是把字符集中的字符编码为特定的二进制数,以便在计算机中存储。编码方式一般就是对二维表的横纵坐标进行变换的算法。一般都比较简单,直接把横纵坐标拼一起就完事了,如ASCII。后来随着字符集的不断扩大,为了节省存储空间,才出现了各种各样的算法, utf-8,utf-16。 字符集和字符编码 一般都是成对出现的,如ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,后续统称为编码(encode,常用于应用程序编码设置)或者 字符集(charset,常用于常用于开发)。 —- 引用摘要: 字符,字符集,字符编码
字符集、字符编码历史发展
早期字符集发展较为独立,各个地区语言文字不一样,存在一定差异, 形成都有各类字符集。各类地区语言文字有时为了应对不同局势和计算机环境,也在不断改变原先字符集同时也改变了当前字符编码规则。后续计算机行业发展迅猛,开始统一全球字符集。
耳熟能详,最早字符集ASCII(American Standard Code for Information Interchange, 美国信息交换标标准代码)。但是ASCII涵盖了现在基础概念“字符集”、“字符集编码”。ASCII中字符集指是拉丁字母、阿拉伯数字、英文字符及计算机不可显控制字符等,共计128个字符,使用一个字节存储(0x00 ~ 0x7f)。
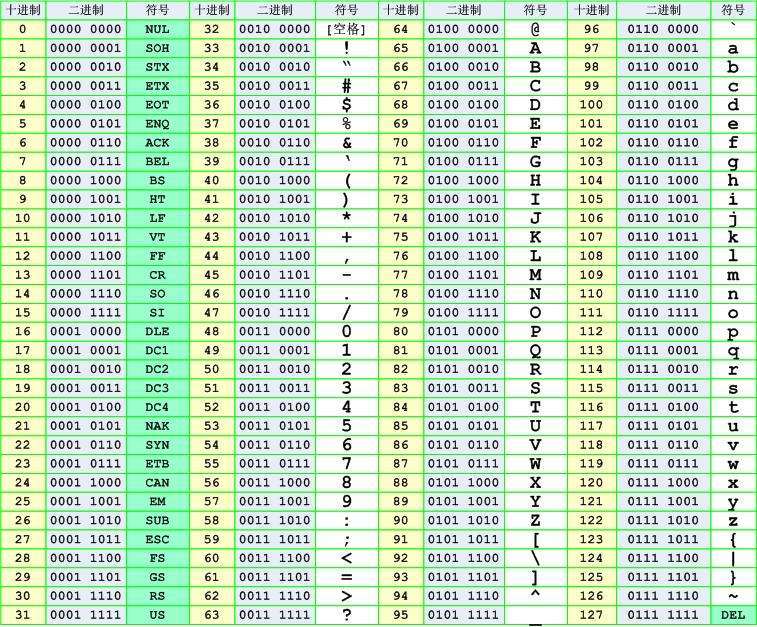
后续发展诞生ISO/IEC 8859标准各类字符集,但是这些字符集ASCII上进行差异性扩展的。其中也包含我们经常使用
latin1(ASCII上增加西欧字符)。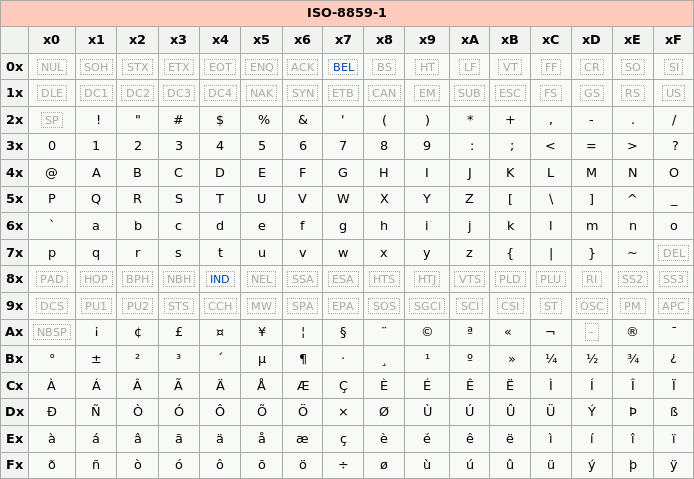
东亚地区地区由于字符数量较多,无法使用单字节编码字符集,开始使用双字节编码字符集、甚至是四个字节编码字符集。中文字符集编码表发展: ASCII -> GB2312 -> GBK -> GB18030, 依次向前兼容,应用时代发展,拓展计算机上可以展示更多中文字符。 详见:程序员必备:彻底弄懂常见的7种中文字符编码
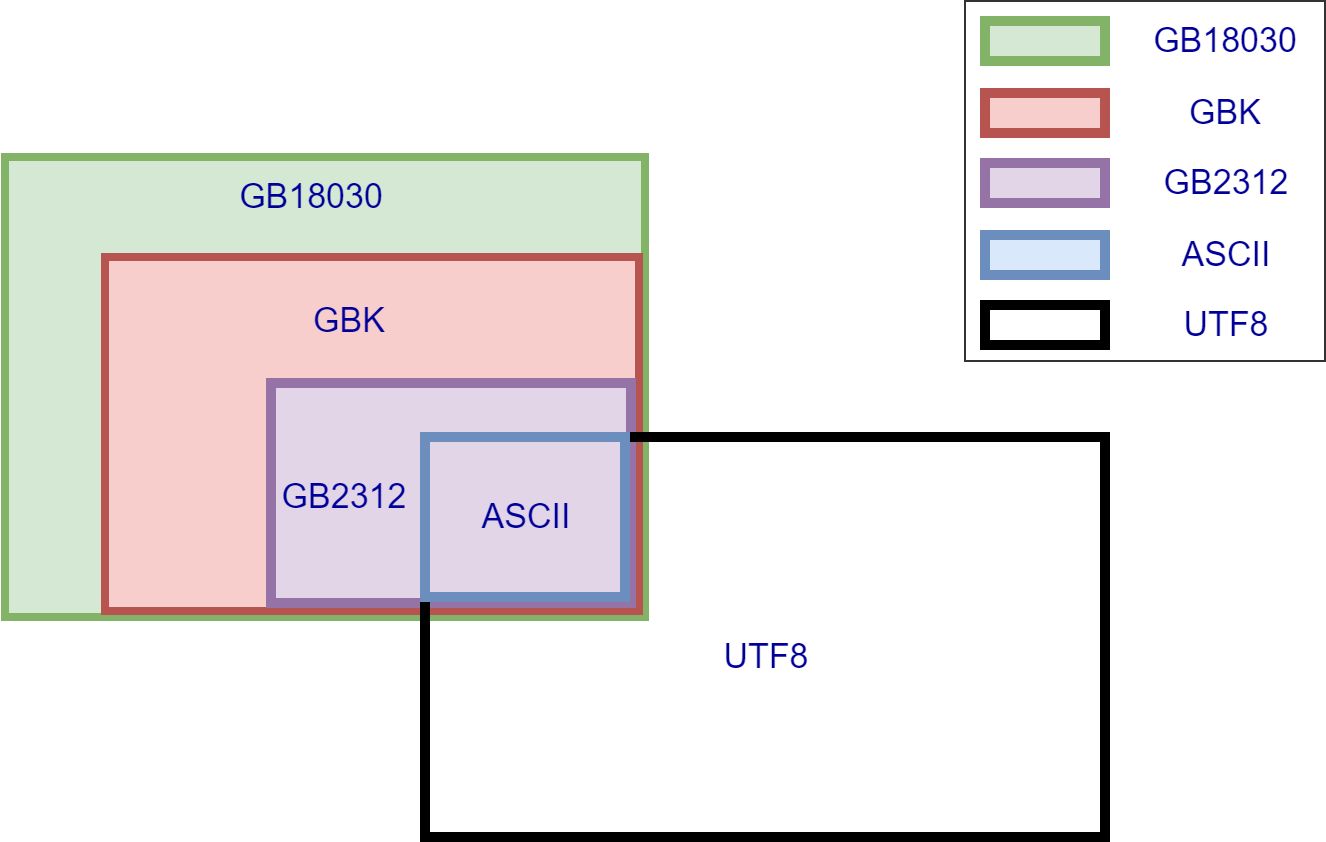
再进一步发展,出现IOS组织领衔UCS和Unicode联盟领衔Unicode来统一全球多语言所有字符。后续两个组织合并成果,共同发展,不断统一Unicode字符集。目前每一个字符,都有一个Unicode值·码位值(码位|码点|
code point),表示是Unicode值的十六进制数的前面加上“U+”,例如“U+0041”代表字符“A”。
字符编码
抽象字符表、编码字符集、字符编码表、字符编码方案
wiki 字符编码
ASCII、GBK、GB18030、LATIN1等字符集将编码字符集和字符编码表是一样的,换句话将字符集编码表的值,不加额外换算,直接转化为二进制存储,编码字符集合字符编码表一样。如ASCII中A,十进制65,十六进制41,二进制01000001,直接将A的二进制存储。
Unicode字符集,该字符集使用4个字节(32位二进制)来表示,属于字符编码里面的编码字符集层次。Unicode的编码空间从U+0000到+10FFFF,共有1,112,064个码位(code point)可用来映射字符,其中从U+D800到U+DFFF之间的码位区段是永久保留不映射到Unicode字符。
Unicode的具体编码方式(字符编码方案)·UTF-8
如果按照Unicode的码点(code point)的二进制直接存储的话,那么对于使用英文国家会造成大量存储空间浪费。因此为了避免这种情况出现,采用不同于码点(code point)的二进制的编码方案存储字符。基于这种情况应用而生有utf-8、utf-16、utf-32。但是目前广泛使用utf-8。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),使用一至四个字节为每个字符编码。
| Unicode范围 | Unicode十六进制 | UTF-8二进制编码格式 | 示例字符->unicode->unicode十六进制->unicode二进制->utf-8二进制-> utf-8十六进制 |
|---|---|---|---|
| U+00 ~ U+7F | 0x00 ~ 0x7F | 0xxxxxxx | A -> U+65 -> 0x65 -> 01000001 -> 01000001 -> 0x65 |
| U+80 ~ U+07FF | 0x80 ~ 0x07FF | 110xxxxx 10xxxxxx | å -> U+E5 -> 0xE5 -> 11100101 -> 11000011 10100101 -> 0xC3A5 |
| U+0800 ~ U+FFFF | 0x0800 ~ 0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx | 严 -> U+4E25 -> 0x4E25 -> 01001110 00100101 -> 11100100 10111000 10100101 -> 0xE4B8A5 |
| U+100000 ~ U+10FFFF | 0x100000 ~ 0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx10xxxxxx | 😀 -> U+1F600 -> 0x1F40 -> 00000001 11110110 00000000 -> 11110000 10011111 10011000 10001010 -> 0xF09F988A |
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
—摘要至字符编码笔记:ASCII,Unicode 和 UTF-8
拓展: Java存储的
Unicode的具体编码方式(字符编码方案)·UTF-16
UTF-16是最早的Unicode字符集编码方式。
UTF-16是使用两个定长字节来表示Unicode的字符。但是两个字节只能表达65,536字符,无法完全表达所有Unicode的字符,后续使用四个字节直接来表达不在基本平面Unicode的字符。
在基本平面中,U+D800 ~ U+DBFF(1024个码点)这一码值范围被称为高代理码点,U+DC00 ~ U+DFFF(1024个码点)这一码值范围被称为低代理码点。这两个高代理码点后面紧接低代理码点便构成了一个代理对,它们代表了不在基本平面之中的1,048,576(1024 × 1024)个码点。
JAVA开发应用
Java 编码的基础知识
Java的char是两个字节,使用UTF-16来表达Unicode的所有字符。对于Unicode的编码空间在U+0000 ~ U+FFFF的可以直接使用char来表示,但是对于Unicode的编码空间U+1FFFF ~ U+10FFFF使用UTF-16的高代理码点和低代理码点的两个char来标识。详见今日 Unicode 字符集及其编码方式
1 | System.out.println("控制台输出字符编码方式:" + Charset.defaultCharset().name()); |
Java不同场景编码转换
有些难度理解,输入和输出都是需要字符编码选择,JVM内部使用UTF-16编码存储在内存上,对于class文件的字符是Modified UTF-8进行编码存储的。JVM使用Modified UTF-8编码把class文件读取, 使用UTF-16编码格式进入内存。使用Unicode作为编码方式的转换。
J VM和OS之间输入输出需要进行编码转换。
-Dfile.encoding=UTF-8控制着Charset.defaultCharset()的输出值
配置的是jvm输入流、输出流默认使用的编码/解码方式。-Dsun.stdout.encoding=GBK配置的控制台标准输出流的编码方式。
字符排序
梳理 MySQL 字符集的相关概念
MySQL字符集和排序规则
Character Sets and Collations in MySQL
总结
简单来说:Unicode、GBK和Big5码等就是编码的值(也就是术语“字符集”),而UTF-8、UTF-16、UTF32之类就是这个值的表现形式(即术语“编码格式”)。
目前编码(encode,常用于应用程序编码设置)或者 字符集(charset,常用于常用于开发)。
附录
Unicode的码点分高代理码点、低代理码点、非字符码点、保留码点、私有码点。Unicode的编码空间可以划分为17个平面(plane),每个平面包含216(65,536)个码位。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从00到10,共计17个平面。Unicode各个平面描述:
| 平面 | 平面位置 | 始末字符值 | 描述 |
|---|---|---|---|
| 基本平面,BMP | 0 | U+0000 - U+FFFF | 绝大部分常用现代文字,如英文、中文、日语、法语等 |
| 补充平面,SMP | 1 | U+10000 - U+1FFFF | 古代字体、音符、扑克牌、麻将、表情emoji符号 |
| 表意补充,SIP | 2 | U+20000 - U+2FFFF | CJKV(中、日、韩、越)的增补文字,如《康熙字典》中非现代字 |
| 表意文字,TIP | 3 | U+30000 - U+3FFFF | |
| 未使用 | 4-13 | U+40000 - U+DFFFF | |
| 特别用途补充平面,SSP | 14 | U+E0000 - U+EFFFF | 特殊控制字符,比如字符变换选器 |
| 15号平面 | 15 | U+F0000 - U+FFFFF | 保留作为私人使用区(A区) Private Use Area-A,简称PUA-A |
| 16号平面 | 16 | U+100000 - U+10FFFF | 保留作为私人使用区(B区)Private Use Area-B,简称PUA-B |
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格”(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
| 对比 | UTF-8 | UTF-16 | UTF-32 | UCS-2 | UCS-4 |
|---|---|---|---|---|---|
| 编码空间 | 0-10FFFF | 0-10FFFF | 0-10FFFF | 0-FFFF | 0-7FFFFFFF |
最少编码字节数(码元·code unit) |
1 | 2 | 4 | 2 | 4 |
| 最多编码字节数 | 4 | 4 | 4 | 2 | 4 |
| 是否依赖字节序 ( Little endian·第二个字节在前/Big endian·第一字节在前) |
否 | 是 | 是 | 是 | 是 |
参考资料
优秀
程序员必备:彻底弄懂常见的7种中文字符编码
十分钟搞清字符集和字符编码
字符编码笔记:ASCII,Unicode 和 UTF-8
从Unicode到emoji
从外部编码的角度再议 Java 乱码问题
基础知识
JAVA中进制相互转换
字体编辑中日韩汉字Unicode编码表
Unicode 表情包
unicode 表
Java class 文件查看器
早期
字符集:ASCII,GB2312,Unicode,UTF-8,ANSI
特殊字符(包括emoji)梳理和UTF8编码解码原理
char 码点和代码单元
